Decoding LLM Performance: A Guide to Evaluating LLM Applications
Exploring frameworks and strategies for evaluating LLM Applications

So, you’ve successfully deployed your LLM app in production. Congratulations! But what now? How do you assess its performance? Perhaps you’re in the process of building out your app and looking for ways to improve its capabilities. So in this post, I’ll walk you through how you can systematically evaluate your LLM applications.
In the following sections, we’ll delve into the nuances of LLM evaluation, exploring traditional metrics, their limitations, and the innovative approaches that are setting new standards in the field. By the end of this guide, you’ll be equipped with the knowledge and latest tools to evaluate, refine, and perfect your LLM-driven applications. Let’s begin!
What is Evaluation?
Evaluation, often shortened as ‘Evals’, is the systematic assessment and measurement of the performance of LLMs and their applications. Think of evaluations as a series of tests and metrics meticulously crafted to judge the “production-readiness” of your application.
Evals are more than just tools for identifying strengths and weaknesses; they are crucial instruments that offer deep insights into how your app interacts with user inputs and real-world data. Robust evaluation of your application means ensuring that it not only adheres to technical specifications but also resonates with user expectations and proves its worth in practical scenarios.
So, if you’ve ever found yourself pondering, “How do I measure the performance of a new model or prompt?” — evaluation is your answer. It’s about turning qualitative questions into quantifiable data, transforming how we understand and improve our AI solutions.
Why evaluate?
The need for rigorous evaluation of LLM applications cannot be overstated. As the adage goes,
“What gets measured gets managed”
If you don’t measure it, you can’t improve it. This holds particularly true in the dynamic and ever-evolving world of Large Language Models.
Whether you’re a seasoned AI developer, a product owner, or a founder, understanding how to evaluate these complex systems is critical to your application’s success.
It’s not just about ensuring that your app functions correctly; it’s about pushing the boundaries of what’s possible, enhancing performance, and, most importantly, building trust in your AI solutions.
If you’re not convinced yet, here are a few more reasons you should consider evaluations —
- A variety of moving parts can be optimized to improve performance and decrease costs.
- Model vendors are constantly updating the base model and developing new ones. Evals help us know which is best for the use case.
- Just because your new prompt looks better on a few examples, doesn’t mean it’s better in general.
What makes a good eval?
It’s important to have a sound framework for evaluation, as you’ll be using its results to make important decisions. A good evaluation is —
- Correlated with outcomes
- A single metric (or small number of metrics)
- Fast and automatic to compute
- Tested on a diverse & representative dataset
- Highly correlated with human judgment
If your evaluation strategy ticks these boxes, you can rest assured that the results of your evals will lead to actionable insights, and eventually guide you to iteratively improve your app’s performance.
But before we delve into the actual evaluation process, let’s briefly look back to reflect on the journey in NLP that has brought us here.
Traditional Evaluation Metrics
Evaluation metrics and benchmarking have long been the cornerstone of progress in research, particularly in fields driven by data and innovation. This is especially true in the realm of Natural Language Processing (NLP), where robust evaluation metrics and benchmarks underpin the rapid pace of advancement.
In NLP, traditional metrics have played a pivotal role in shaping our understanding of language models and their capabilities. From precision and recall to BLEU and ROUGE scores, these metrics have offered a way to quantitatively assess the performance of various models and algorithms. They have been crucial in benchmarking progress, comparing different approaches, and setting the direction for future research and development.
However, as the complexity of language models, especially LLMs, continues to grow, the limitations of traditional metrics become increasingly apparent. This shift calls for re-evaluating how we measure success and effectiveness in NLP, leading to the exploration of more refined metrics that can keep pace with the advancements in the field.
Limitations of Traditional Metrics
While traditional metrics have been instrumental in the progress of NLP, they come with inherent limitations, particularly when applied to the complexities of modern LLMs. These limitations primarily arise from the metrics’ inability to fully capture the nuanced understanding and generation of human language.
Take, for instance, the BLEU (Bilingual Evaluation Understudy) score, a common metric used in machine translation. BLEU evaluates the quality of translated text by comparing it with a set of high-quality reference translations. However, its focus is predominantly on the precision of word matches, often overlooking the context and semantics.
As a result, a translation could score high on BLEU for having words in technically correct order, but still miss the mark in conveying the right tone, style, or even meaning as intended in the original text.
This example underscores how traditional metrics can misrepresent text similarity and fail to capture semantic equivalence, especially when different wording with similar meanings is used. As such, this raises concerns about their reliability in evaluating the complex outputs of LLMs, which often require a deeper understanding of context and meaning, beyond mere word overlap.
Non-traditional Metrics
Unlike their predecessors, non-traditional metrics strive to capture the meaning of language. These metrics aim to provide a more accurate understanding of the context and quality of the text generated by language models, especially for tasks that require more than syntactic correctness. Some notable non-traditional metrics are —
- BERTScore: Utilizes BERT embeddings to compare the similarity of words and phrases within the output and reference texts, providing a more refined measure of semantic equivalence.
2. BLEURT: A learned metric based on BERT that has been trained on human judgments. It predicts the quality of text generation more accurately by considering context and semantics.
3. Entailment Score: Measures the degree to which the output of a language model logically follows from a given premise or input. This NLI (Natural Language Inference) metric assesses the model’s understanding of logical relationships within the text, which is crucial for tasks such as summarization and question answering.

As LLMs continue to evolve, the evaluation metrics must also adapt, moving beyond surface-level analysis to capture the intricacies of human language and thought processes.
The Evolution of Evaluation: The Rise of LLM-Assisted Evals ⚖️
As language models have grown in complexity and capability, our evaluation strategies have evolved in parallel. In the early days of transformer-based language models like BERT and BART, researchers sought to overcome the limitations of traditional metrics by leveraging the language models themselves. This gave rise to non-traditional metrics like BERTScore, which leverages BERT’s contextual embeddings to assess semantic similarity more effectively than simple n-gram matching.
This innovative approach marked a significant shift in evaluation methods, reflecting a broader trend: the tools we develop to understand human language are also becoming the benchmark for evaluating themselves. As these language models advanced, the metrics evolved from non-traditional to what we can now refer to as LLM-assisted evals.
In the current era of modern LLMs, the same principle applies but on a more sophisticated scale. Researchers are now employing LLMs like GPT-4 to evaluate the outputs of similar models. This recursive use of LLMs for evaluation underscores the continuous cycle of improvement and refinement in the field. By using LLMs as both the subject and the tool of evaluation, we unlock a deeper level of introspection and optimization.
LLM-assisted metrics represent the natural progression of this evolutionary path. They exemplify the concept of “evaluation by the evaluated,” where the very models we seek to measure are put to the task of self-assessment. This not only highlights the versatility and power of LLMs but also illustrates a fundamental principle in AI development:
The tools we create to understand and generate language are simultaneously becoming the yardstick by which we measure their progress.
This constant evolution of evaluation keeps pace with the relentless progress of language models themselves, ensuring that our benchmarks are as dynamic and nuanced as the technologies they seek to measure.
LLM-assisted metrics harness the capabilities of LLMs to judge, score, and provide feedback on the performance of their peers. Some of the most impactful papers that have popularized this approach include:
- GPTScore: A novel evaluation framework that leverages the zero-shot capabilities of generative pre-trained models for scoring text. Highlights the framework’s flexibility in evaluating various text generation tasks without the need for extensive training or manual annotation.
- LLM-Eval: A method that evaluates multiple dimensions of conversation quality using a single LLM prompt. Offers a versatile and robust solution, showing a high correlation with human judgments across diverse datasets.
- LLM-as-a-judge: Explores using LLMs as a surrogate for human evaluation, tapping into the model’s alignment with human preferences. Demonstrates that LLM judges like GPT-4 can achieve an agreement rate exceeding 80% with human evaluations, suggesting a scalable and effective method for approximating human judgments.
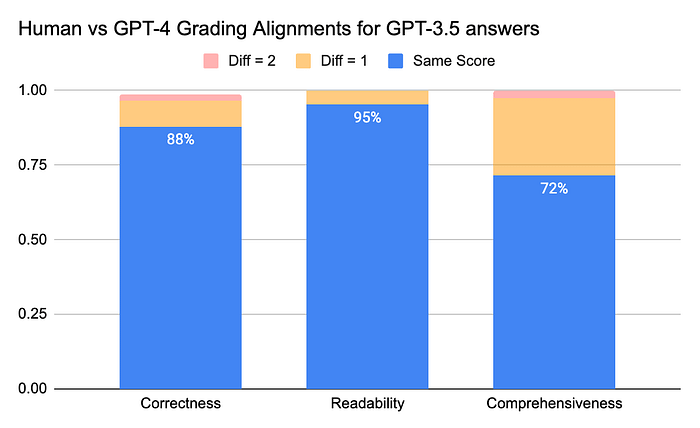
Limitations of LLM-Assisted Evaluations
While LLM-assisted evaluations represent a significant leap in NLP, they are not without their drawbacks. Recognizing these limitations is key to ensuring accurate and meaningful assessments.
- Application-Specific: One major constraint is that LLM-driven evaluators produce application-specific metrics. A numeric score given by an LLM in one context does not necessarily equate to the same value in another, hindering the standardization of metrics across diverse projects.
- Position Bias: According to a study, LLM evaluators often show a position bias, favoring the first result when comparing two outcomes. This can skew evaluations in favor of responses that appear earlier, regardless of their actual quality.
- Verbose Bias: LLMs also tend to prefer longer responses. This verbosity bias means that more extended, potentially less clear answers may be favored over concise and direct ones.
- Self-Affinity Bias: LLMs may exhibit a preference for answers generated by other LLMs over human-authored text, potentially leading to a skewed evaluation favoring machine-generated content.
- Numerical and Stylistic Biases: LLMs have been observed to prefer specific numbers when scoring responses and favor their own style of answering over human responses.
- Stochastic Nature: The inherent fuzziness within LLMs means they might assign different scores to the same output when invoked separately, adding an element of unpredictability to the evaluation.
To mitigate these biases and improve the reliability of LLM evaluations, several strategies can be employed:
- Position Swapping: To counteract position bias, swapping the reference and the result in evaluations ensures the outcome being assessed is in the first position.
- Few-shot Prompting: Introducing a few examples or prompts into the evaluation task can calibrate the evaluator and reduce biases like verbosity bias.
- Hybrid Evaluation: To achieve a more grounded evaluation, integrating LLM-based assessments with human judgment or advanced non-traditional metrics can be highly effective. This strategy leverages the effectiveness of LLMs and, precise context-aware insights provided by metrics like BERTScore or Entailment. This combined approach offers a comprehensive assessment framework that balances the innovative capabilities of LLMs with the proven accuracy of non-traditional metrics.
Incorporating these strategies can help navigate the limitations of LLMs, leading to more accurate and reliable evaluations of free text and LLM-driven applications.
From Theory to Practice: Evaluating Your LLM Application 🔍
Now that we’ve explored the progression of evaluation methods, and equipped with an array of techniques at our fingertips, let’s embark on the practical journey of evaluating an LLM application.
The choice of evaluation strategy will largely depend on the type of LLM application you are assessing, so it’s important to choose wisely. Here’s a broad categorization of LLM applications, each with its unique context:
- Simple LLM Wrappers: User-friendly interfaces that connect users directly with an LLM for general-purpose tasks like summarization, extraction, and content generation.
- RAG (Retrieval Augmented Generation): Complex systems that combine LLMs with additional data sources to enrich the model’s responses with more precise and contextually relevant information.
- Agents: Advanced autonomous agents equipped with multi-step reasoning, capable of navigating complex tasks that mimic a human’s decision-making process.
The evaluation approach for each of these application types will differ, tailored to their specific functionalities and user requirements.
Evaluation Methodology
The journey of evaluating an LLM application ideally follows a structured framework, incorporating a suite of specialized tools and libraries. By systematically applying evaluation methods, we can gain meaningful insights into our applications, ensuring they meet our standards and deliver the desired outcomes.
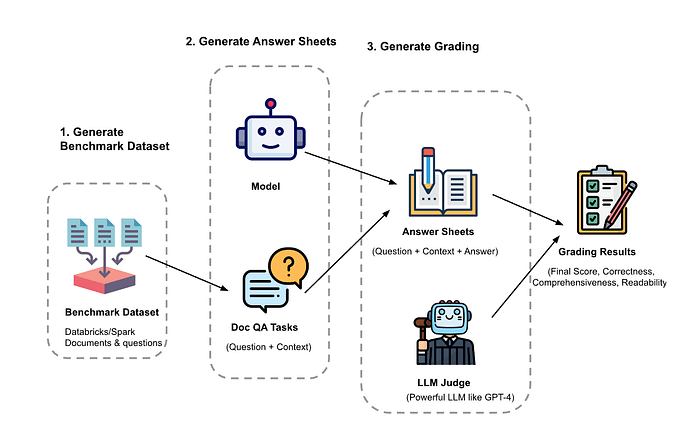
Step 1. Crafting a Golden Test Set:
The evaluation begins with the creation of a benchmark dataset, which should be as representative as possible of the data the LLM will encounter in a live environment. This is often referred to as a ‘gold test set’ — the standard against which the LLM’s performance is measured.
- Why ‘Golden’?: This dataset is ‘golden’ because it’s the ideal, the benchmark of truth against which all responses are compared. It’s the data set that defines what correct answers look like for the specific tasks your LLM is designed to perform.
- Production Data vs. Synthetic Sets: The ultimate goal is to have your evaluation test set encompass actual production data, allowing for an accurate measure of your app’s real-world performance. If production data isn’t available, starting with a synthetic test set is a practical alternative. This synthetic set should mimic production scenarios as closely as possible, ensuring your LLM is tested against realistic challenges.
To illustrate, I’ll create a test set specifically for evaluating SPARK, the RAG system I developed in my previous article, and also since RAG has become increasingly prevalent in production-level LLM applications due to their robustness and versatility.
Many libraries allow us to generate test synthetic test sets, such as Langchain’s QA generation chain, llama-index, and ragas, each utilizing unique techniques to generate an effective test set.
The creation of a diverse and representative dataset is a crucial step, that sets the foundation for a holistic assessment of your LLM application. In this context, I utilized RAGAS’ test-set generation feature; whose approach to creating evaluation sets is particularly effective in mirroring real-world scenarios, making it an excellent choice for accurately measuring an application’s performance.
from ragas.testset import TestsetGenerator
testsetgenerator = TestsetGenerator.from_default()
test_size = 50
spark_testset = testsetgenerator.generate(documents, test_size=test_size)
spark_testset.to_pandas()Step 2. Grading the Results:
Once we have our evaluation test set complete with ground truth and responses generated by our LLM application, the next step is to grade these results. This phase involves using a mix of LLM-assisted evaluation prompts and more integrated, hybrid approaches.
Thankfully, we’re not short on tools for this task. There’s a plethora of open-source libraries equipped with ready-to-use evaluation prompts, each offering unique features and methodologies. Let’s explore some of the most prominent and useful Python libraries for LLM application evaluation:
Langchain
Langchain is renowned for streamlining development with high-level abstractions and a comprehensive ecosystem for crafting LLM-driven applications. If Langchain is already part of your app’s toolkit, evaluating is a seamless process with its evaluation module.
LangChain’s evaluators come with ready-to-use implementations and a customizable API. The main types of evaluators include:
- String Evaluators: Assess the accuracy of predicted strings against reference strings, ensuring the fidelity of model outputs.
- Trajectory Evaluators: Analyze the entire trajectory of actions taken by an agent, drawing insights into decision-making processes.
- Comparison Evaluators: Designed for contrasting outcomes of two different runs on the same input, aiding in comparative analysis.
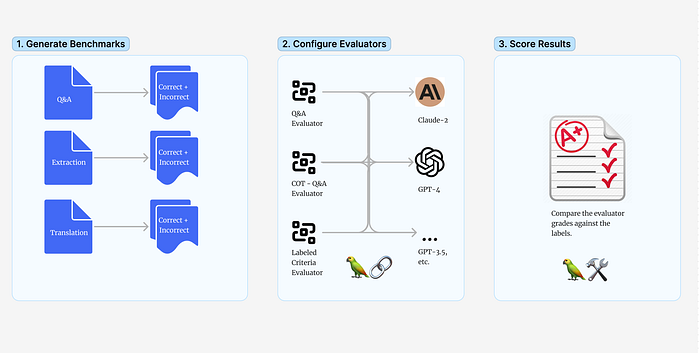
Additionally, the Langchain team has contributed an open-source evaluation tool, named auto-evaluator. This handy streamlit app is equipped with various tunable knobs and configurations, enabling us to conduct and log diverse experiments effectively.
An example of defining a custom criteria evaluator with Langchain is as follows -
custom_criterion = {
"numeric": "Does the output contain numeric or mathematical information?"
}
eval_chain = load_evaluator(
EvaluatorType.CRITERIA,
criteria=custom_criterion,
)
query = "Tell me a joke"
prediction = "What do you get when you divide the circumference of a pumpkin by its diameter? Pumpkin Pi."
eval_result = eval_chain.evaluate_strings(prediction=prediction, input=query)
print(eval_result){'reasoning': "The joke's use of 'Pi' in 'pumpkin Pi' contains mathematical content, cleverly referencing the mathematical constant π. This satisfies the criterion for numeric or mathematical information. Thus, it meets the evaluation standard.\n\nY", 'value': 'Y', 'score': 1}Llama-Index
Llama-index is increasingly gaining popularity for its focus on production-readiness and advanced retrieval modules, often being preferred over Langchain. It also offers a comprehensive suite of evaluation tools for RAG applications, categorized into:
- Response Evaluation: Ensures the response is in line with the retrieved context, query, and any reference answers or guidelines.
- Retrieval Evaluation: Gauges how relevant the retrieved sources are to the original query.
A simple example of using the faithfulness evaluator to detect hallucinations with llama-index is as follows —
from llama_index import VectorStoreIndex, ServiceContext
from llama_index.llms import OpenAI
from llama_index.evaluation import FaithfulnessEvaluator
# build service context
llm = OpenAI(model="gpt-4", temperature=0.0)
service_context = ServiceContext.from_defaults(llm=llm)
# build index
...
# define evaluator
evaluator = FaithfulnessEvaluator(service_context=service_context)
# query index
query_engine = vector_index.as_query_engine()
response = query_engine.query(
"What is adversarial prompting?"
)
eval_result = evaluator.evaluate_response(response=response)
print(str(eval_result.passing))RAGAS
RAGAS, short for ‘RAG Assessment’, is emerging as a leading library for evaluating RAG pipelines, and also one of my favorite evaluation tools. Celebrated for its comprehensive approach, RAGAS leverages the latest research to provide in-depth analysis and hybrid evaluation of RAG performance. The framework has even garnered recognition from OpenAI on dev-day, highlighting its utility and effectiveness.

RAGAS is not just about evaluating; the vision is to establish an open-source standard for continuous improvement, embracing the philosophy of ‘Metrics Driven Development’ (MDD) — a data-centric approach that emphasizes using critical metrics to make informed decisions for ongoing enhancement of products. Its key features include —
- Test Set Generation: Provides a novel approach to evaluation data generation, using an evolutionary generation paradigm to create synthetic test sets that encompass various types of questions encountered in production.
- Integrations: Includes built-in integrations with popular libraries like LangChain, Llama-index, and Deep-Eval. This integration capability enhances its versatility, allowing users to combine the strengths of different tools for a more comprehensive evaluation.
- Hybrid Evaluation: To address the limitations of traditional LLM evaluations, RAGAS employs a hybrid approach. It incorporates traditional NLP metrics like BERTScore and NLI for well-rounded evaluations. Additionally, it uses self-consistency methods, making multiple LLM calls to average out any stochastic errors and ensure reliability in the evaluation results.
RAGAS’ approach to LLM evaluation is research-driven and holistic, focusing on continuous improvement and accuracy in assessing the performance of RAG applications.
Running the evaluations is as easy as calling evaluate on your test set with the metrics of your choice —
from ragas import evaluate
result = evaluate(
spark_testset,
metrics=[
context_precision,
faithfulness,
answer_relevancy,
context_recall,
],
)
result
df = result.to_pandas()
df.head()TruLens
TruLens by TruEra is an innovative tool and a notable contender in the world of Large Language Model Operations (LLMOps). It helps developers objectively measure the quality and effectiveness of LLM-based applications using a set of feedback functions, for feedback-driven analysis, interpretability, and effectiveness metrics.
These feedback functions enable developers to programmatically evaluate the quality of inputs, outputs, and intermediate results. The library is versatile, supporting a wide range of use cases and integrations. Key features include:
- Experimentation and Tracking: TruLens fills a gap in the LLMOps tech stack by supporting developers with tools to evaluate and track experiments, scaling up the human review steps in the LLM app development process.
- Comprehensive Feedback Functions: It includes a variety of feedback functions to evaluate different aspects of LLM apps, such as Groundedness, Relevance, Toxicity, Language Mismatch, Response Verbosity, and more. These functions allow for detailed analysis of app performance and identify areas for improvement.
- Dashboard for Insights: After running feedback functions, developers can view the aggregate results on a leaderboard and drill down into experiment versions to understand their quality and potential failure modes.
TruLens ships with integrations for Langchain and Llama-index, as well as with standard Python applications, out-of-the-box. Here’s an example of using feedback functions with a Langchain app —
from trulens_eval.feedback.provider import OpenAI
import numpy as np
# Initialize provider class
openai = OpenAI()
# select context to be used in feedback. the location of context is app specific.
from trulens_eval.app import App
context = App.select_context(langchain_rag_chain)
from trulens_eval.feedback import Groundedness
grounded = Groundedness(groundedness_provider=OpenAI())
# Define a groundedness feedback function
f_groundedness = (
Feedback(grounded.groundedness_measure_with_cot_reasons)
.on(context.collect()) # collect context chunks into a list
.on_output()
.aggregate(grounded.grounded_statements_aggregator)
)
# Question/answer relevance between overall question and answer.
f_qa_relevance = Feedback(openai.relevance).on_input_output()
# Question/statement relevance between question and each context chunk.
f_context_relevance = (
Feedback(openai.qs_relevance)
.on_input()
.on(context)
.aggregate(np.mean)
)Deep-Eval
DeepEval stands out as an open-source evaluation framework for LLM applications, offering simplicity and specialization akin to Pytest for unit testing LLMs. It evaluates performance using a diverse range of built-in metrics as well as custom metrics, using LLMs and other NLP models.
deepeval: SourceIt is built to be compatible with Pytest and aims to make evaluation as easy as writing a unit test, seamlessly integrating with existing CI/CD pipelines. Key features of DeepEval include:
- Diverse Evaluation Metrics: Use a variety of default metrics like Hallucination, Answer Relevance, Bias, Toxicity, and more.
- Custom Metric Creation: Easily create and define custom metrics.
- Confident AI Dashboard: Also provides a user-friendly UI, allowing users to log and view all test results, debug LLM traces, manage evaluation datasets, and track live events for continuous evaluation in a production setting.
A simple evaluation test case using deep-eval is as follows —
import pytest
from deepeval import assert_test
from deepeval.metrics import AnswerRelevancyMetric
from deepeval.test_case import LLMTestCase
def test_case():
input = "What is self-consistency?"
context = ["Self-consistency is an approach that simply asks a model the same prompt multiple times and takes the majority result as the final answer. It is follow up to CoT, and is more powerful when used in conjunction with it."]
# Replace this with the actual output from your LLM application
actual_output = "Self-consistency is an approach used in prompt engineering that involves asking a model the same prompt multiple times and taking the majority result as the final answer. It is often used in conjunction with the Chain of Thought (CoT) technique to enhance the model's performance."
answer_relevance_metric = AnswerRelevancyMetric(minimum_score=0.7)
test_case = LLMTestCase(input=input, actual_output=actual_output, retrieval_context=context)
assert_test(test_case, [answer_relevance_metric])Arthur Bench
Arthur Bench is another robust open-source tool developed by Arthur to help evaluate and compare large language models (LLMs), prompts, and hyperparameters. It provides a full suite of scoring metrics, allows the creation of custom benchmarks, and enables developers to test and compare the performance of different models quantitatively.

The tool aims to assist in making data-driven decisions when selecting and validating LLMs, as well as optimizing their budget and privacy considerations. Arthur Bench is available both as a local version via GitHub and as a cloud-based SaaS offering. Key features include —
- Standardized Evaluation Workflow: Bench offers a unified interface for LLM evaluation across diverse tasks and use cases, promoting consistency and ease in the evaluation process.
- Comparative Analysis: It allows for comparison between open-source and closed-source LLMs, providing insights into their performance on specific data sets.
- Bench Dashboard: Bench also includes a user-friendly dashboard that enables users to view and analyze test suite results, offering a clear visualization of performance metrics and comparisons.
To create a test suite, all you need to specify is a name, data, and scorer. Here’s a simple example of a test suite using the exact_match scorer:
from arthur_bench.run.testsuite import TestSuite
# Create a test suite
suite = TestSuite(
"bench_quickstart",
"exact_match",
input_text_list=["What year was FDR elected?", "What is the opposite of down?"],
reference_output_list=["1932", "up"]
)
# Run the test suite
suite.run("quickstart_run", candidate_output_list=["1932", "up is the opposite of down"])
# For existing test suites
existing_suite = TestSuite("bench_quickstart", "exact_match")
existing_suite.run("quickstart_new_run", candidate_output_list=["1936", "up"])
# To view the results, run `bench` from the command line (with server dependencies installed)
# benchUpTrain
UpTrain is a highly versatile and underrated library designed for evaluating LLM applications, emphasizing simplicity and ease of use. It’s tailored to quantify performance across various dimensions of your LLM app, as well as configuring custom checks and grading prompts.
Their approach to LLM evaluation is built with customization and developer convenience in mind, making it a powerful tool for evaluating a wide range of LLM applications. Key features of UpTrain:
- Diverse Metrics: Provides thoughtful evaluations covering aspects like factual accuracy, response completeness, tone critique, guideline adherence, and more. This comprehensive suite ensures a thorough assessment of LLM responses.
- A/B Testing: Facilitates split testing, allowing users to experiment with different prompts. This feature is crucial for fine-tuning prompt strategies to determine the most effective options for specific applications.
- Conversation Evaluation: UpTrain stands out as one of the few libraries offering conversation evaluation metrics. It includes the ‘Conversation Satisfaction’ metric, which assesses user satisfaction based on the completeness and acceptance of the conversation with the AI assistant.
UpTrain’s focus on both technical robustness and practical usability makes it a valuable library to enhance LLM applications. Here’s a simple example showcasing the ease of using some of the built-in evaluators—
from uptrain import EvalLLM, Evals, CritiqueTone
import json
OPENAI_API_KEY = "sk-***************"
data = [{
'question': 'What is prompt ensembling?',
'context': "Prompt ensembling is the concept of using multiple different prompts to try to answer the same question. There are many different approaches to this.DiVeRSe ('Diverse Verifier on Reasoning Steps') is a method that improves the reliability of answers in a threefold manner.",
'response': 'Prompt ensembling is a technique used in prompt engineering to improve the reliability and performance of AI models. It involves using multiple different prompts to generate responses to the same question or task. By generating diverse completions from different prompts, prompt ensembling aims to increase the accuracy and robustness of the models responses'
}]
eval_llm = EvalLLM(openai_api_key=OPENAI_API_KEY)
results = eval_llm.evaluate(
data=data,
checks=[Evals.CONTEXT_RELEVANCE, Evals.FACTUAL_ACCURACY, Evals.RESPONSE_RELEVANCE, CritiqueTone(persona="teacher")]
)
print(json.dumps(results, indent=3))Final Step: Aggregate Results and Glean Insights
After exploring various evaluation libraries and experimenting with different configurations in your LLM application, the final step is to consolidate and analyze these findings.
This stage is all about aggregating the results from each test run. By now, you’ve hopefully conducted various experiments with different evaluators and configurations for your app. Whether it’s swapping out retrieval algorithms, trying new prompts, or adjusting other hyper-parameters, each change contributes to a deeper understanding of your application’s performance.
The goal here is to synthesize these varied results to gain a comprehensive view of how each change impacted your app’s performance. Through aggregation, you’ll be able to compare and contrast the efficacy of different configurations against your test set. By doing so, you can pinpoint which approach or combination of approaches yielded the most effective performance for your application.
This process isn’t just about identifying the highest scores; it’s an opportunity to uncover deeper insights into what works best for your application and why. By thoroughly analyzing these final results, you can ultimately make decisions on optimizing and refining your LLM application for enhanced performance.
In essence, the final step helps you transition from experimentation to informed decision-making, guiding you toward continuous improvement and innovation in your LLM application.
Conclusion
Navigating the landscape of LLM evaluation is a multifaceted endeavor. From understanding the fundamental ‘what’ and ‘why’ of evaluation, to delving into both traditional and modern metrics, this journey provides an essential toolkit for anyone working with LLM applications.
In this guide, we’ve traversed the path from the theoretical underpinnings of evaluation metrics to their practical applications in real-world scenarios. By exploring various tools and methodologies, and through the systematic process of generating test sets, grading results, and aggregating insights, we’ve illuminated the nuances of LLM evaluation.
The journey doesn’t end here. The field of NLP and LLMs is constantly evolving, with new challenges and breakthroughs emerging every day. As you continue to refine and enhance your LLM applications, remember that the process of evaluation is iterative and dynamic. It’s not just about reaching a destination but about ongoing exploration and adaptation.
As we conclude, I hope this serves as a valuable resource, providing clarity and direction in your endeavors with LLM applications. May it aid you in making informed decisions, fostering innovation, and ultimately contributing to the advancement of this exciting field!
If you liked this post, follow me on LinkedIn, and feel free to reach out if you have any queries :)
Resources and References
- Evaluating LLM-based Applications
- Databricks: Best Practices for LLM Evaluation
- RAGAS: All about evaluating LLMs
- Trulens: Evaluate and Track your LLM Experiments
- Confident AI: How to evaluate LLM Applications
- LLM Evaluation: The Definitive Guide To Building and Benchmarking Evals
- Humanloop: How to Maximize LLM Performance
- Langchain: How “correct” are LLM Evaluators?
- Autgen: How to assess utility of LLM-powered Applications?
- Evaluating an LLM application for generating free-text narratives in financial crime
- Evaluating large language model applications with LLM-augmented feedback
- Cohere: Evaluating LLM Outputs
- Navigating LLM Evaluations: Why it Matters for Your LLM Application
Read more by me —
